AbhigyaninGeek CultureCross-Validation TechniquesThis article aims to explain different Cross-Validation techniques and how they work.Aug 30, 20212Aug 30, 20212
AbhigyaninAnalytics VidhyaDifferent types of Hyper-Parameter Tuning.This article aims to show python implementation for different Hyperparameter Tuning techniques using the RandomForest model.Jul 17, 2021Jul 17, 2021
AbhigyaninAnalytics VidhyaBuilding, Containerizing and Deploying a News Classifier AppThis article is all about the end-to-end project of News Classifier. App has been built using streamlit, containerized with Docker and…Feb 7, 20211Feb 7, 20211
AbhigyaninAnalytics VidhyaProblems with Precision and Recall.We know, that when we have imbalanced data accuracy is not the metrics we should be looking at as it may be misleading, instead we should..Nov 15, 2020Nov 15, 2020
AbhigyaninAnalytics VidhyaUnderstanding Ensemble Techniques!!!Ensemble methods are techniques that create multiple models and then combine them to produce improved results…Sep 27, 2020Sep 27, 2020
AbhigyaninAnalytics VidhyaTechniques to Transform Data Distribution!!!In Machine Learning most of the algorithms work on the assumption of the normal distribution of the data. However not all machine learning…Sep 20, 2020Sep 20, 2020
AbhigyaninAnalytics VidhyaHandling Imbalanced Classes!!!One of the many problems with the real world machine learning classification problems is the issue of the imbalanced data. Imbalanced data…Sep 13, 2020Sep 13, 2020
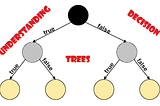
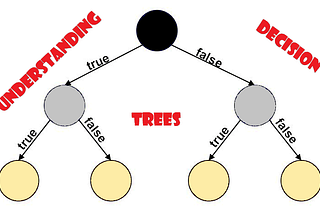
AbhigyaninAnalytics VidhyaUnderstanding Decision Tree!!Decision Trees are a non-parametric supervised learning method used for both classification and regression tasks…Sep 6, 2020Sep 6, 2020
AbhigyaninAnalytics VidhyaUnderstanding Polynomial Regression!!!Polynomial Regression is a special case of Linear Regression where we fit the polynomial equation on the data with a curvilinear…Aug 2, 20203Aug 2, 20203
AbhigyaninAnalytics VidhyaUnderstanding Logistic Regression!!!In my previous Blog, I tried explaining about Linear Regression and how it works.Let’s See why Logistic Regression is one of the important…Jul 26, 20201Jul 26, 20201